LISPUSER
CLISP - GNU CLISPLisp isn't a language, it's a building material.| 公式ページ | http://www.clisp.org/ |
| 最新バージョン | 2.46 |
Table of Contents
CLISP 公式ドキュメントの翻訳
CLISP Common Lisp Summary
英語原文: http://clisp.sourceforge.net/summary.html
Common Lisp は高水準、汎用目的、オブジェクト指向、動的、関数型といった 特徴を備えたプログラミング言語です。
CLISP はドイツの Karlsruhe 大学の Bruno Haible、Munich 大学の Michael Stoll らによって開発された Common Lisp の実装です。ANSI Common Lisp に 規定された標準に加えて、多くの拡張を備えた Lisp です。
CLISP はインタプリタとコンパイラ、デバッガ、CLOS、MOP、FFI、国際化メッ セージ、正規表現、ソケットインターフェース、ここに列挙した以上のものを 含んでいます。CLX、Garnet や CLUE/CLIO を通じて X11 インターフェースが 利用可能ですし、コマンドラインの行編集機能が readline ライブラリによっ て提供されています。また、CLISP は Maxima や ACL2 といったCommon Lisp パッケージを動作させることができます。
CLISP はほとんどの GNU や UNIX ライクなシステム(Linux, FreeBSD, NetBSD, OpenBSD, Solaris, Tru64, HP-UX, BeOS, NeXTstep, IRIX, AIX …)、 そのほかのシステム(Windows NT/2000/XP, Windows 95/98/ME)で動作します。 最小限必要なメモリは 4MB です。
CLISP は GNU GPL ライセンスの元で配布されるフリーフソフトウェアです。プ ロプライエタリな商用ソフトウェアをCLISP と共に配布することも可能です。 CLISP 配布物のなかの COPYRIGHT ファイルを御覧ください。
ユーザーインターフェースは英語、ドイツ語、フランス語、スペイン語、オラ ンダ語、ロシア語、デンマーク語が提供されており、実行時に変更することが できます。
Common Lisp CLISP
英語原文 http://clisp.sourceforge.net/propaganda.html
Common Lisp は
- 汎用目的のプログラミング言語で、かつ AI 言語でもあります
- 対話的です interactive
- プロフェッショナルユースに使われています
Common Lisp プログラム は
- テストが容易です(対話的)
- メンテナンスが容易です(プログラミングスタイルによりますが)
- ハードウェアや OS プラットフォームや実装を越えて、ポータブルです。 (標準化された言語とライブラリがあります)
我々の Common Lisp 実装 CLISP は
- 最小でたった 4MB のメモリしか要求しません
- ほとんどの ANSI 標準に準拠しています。また沢山の拡張があります。
- 好みのテキストエディタを呼び出せます
- 自由に配布してかまいません
Common Lisp は以下のものを提供します
- 明快な構文、注意深く設計された動作
- さまざまなデータ型 (数値、文字列、配列、リスト、文字、シンボル、構造体、ストリームなど)
- 実行時型づけ: プログラマーは型宣言が必要ありませんが、型に関するエラーは通知されます
- 多くのジェネリック関数: 全ての種類の数値(整数、分数、小数、複素数)に対する 88 の算術演算関数、文字列、配列、リストに対する 44 の検索/フィルタリング/整列関数
- 自動メモリ管理(ガーベージコレクション)
- プログラムをまとめるモジュール機構
- オブジェクトシステム、強力なメソッドコンビネーションを備えたジェネリック関数
- マクロ:すべてのプログラマは、自分用に言語を拡張することができます
我々の Common Lisp 実装 CLISP は以下のものを提供します
- インタプリタ
- 実行速度を 5 倍速くするコンパイラ
- フォームからフォームへとステップ実行可能なソースレベルデバッガ
- サイズ制限のない全てのデータ型(サイズは宣言する必要がありません。リストや配列のサイズは動的に変更されます)
- 任意のサイズの整数
- 制限のない浮動小数点の精度
- 800 を超えるライブラリ関数やマクロ:それらの 600 以上は C で記述されています
CLISP and Unicode
CLISP は Unicode 3.2 を完全にサポートしています。xterm で動作している日本語で書かれた Lisp ファイルを示します。
.. image:: ../files/fibjap-xterm.gif
CLISP and CLX
ここに CLISP の new-clx モジュール(+ xshape 拡張)のデモがあります。(訳注:画像は原文参照)
.. image:: ../files/new-clx-sokoban.gif
CLISP Performance
CLISP は CLOS、入出力、リスト処理、整数演算(CLISP の多倍長整数はほかの Common Lisp 実装の大半よりパフォーマンスが良いです) ほとんどの分野で他 の ANSI CL 実装と同じくらいの速度です。もっとも CLISP が苦手とする分野 は浮動小数点演算の領域です。目立つほどひどく性能が 悪いという点はありま せんし、 Java, Perl, TCL, Scheme インタプリタより良いパフォーマンスです が, CLISP は他のオープンソースな Common Lisp 実装 CMUCL (これは C や FORTRAN と同等程度の性能です)よりは遅いです。もしあなたが数値計算を多 用するならば、おそらく CMUCL を選んだほうが良いでしょう。それ以外では CLISP は賢い選択です。
CLISP 日本語コンテンツ
CLISP の新機能 (2.42)
- GTK2 インターフェースモジュールが追加されました。Glade で GUI が作成できます。(Thanks to James Bailey)
- GDBM モジュールが追加されました。(←私の contribute なので、御意見御要望は日本語で私まで送っていただいても結構です。いろいろ助けてくれた Sam Steingold 氏に感謝!!)
- Meta-Object Protocol のサポートが進みました。
- NEW-CLX の改良とデモの追加
- EXT:ARGLIST がマクロに対しても動作するようになりました
- いろいろバグ修正
CLISP の新機能 (2.41)
- 新しいモジュール libsvm インターフェース http://www.csie.ntu.edu.tw/~cjlin/libsvm が追加されました。 SVM (Support Vector Machine) が CLISP でサポートされます。 詳細は http://clisp.cons.org/impnotes/libsvm.html を見てください。 (訳注: libsvm モジュールは win32 ではまだ利用できません。というか configure みたところ .so しか考えてないみたいでした。 libsvm は win32 でも動作するようなので、configure の修正で対応できるかな?)
- CLISP 2.36 から壊れてた FFI のコールバックが修正された
CLISP の新機能 (2.40)
- OPTIMIZE SPACE のレベルが十分に低く設定されていた場合、 関数のドキュメントとラムダリストが保持されるようになりました 。 http://clisp.cons.org/impnotes/declarations.html#space-decl (訳注: これで、 SLIME の補完時に今迄は arg0 arg1 だったとこが、正しい引数名が表示されます!! )
- 関数 PCRE:PCRE-EXEC は PCRE v6 とともにコンパイルされた場合に :DFA 引 数を受けとり、 pcredfaexec() を呼ぶようになりました。詳細は http://clisp.cons.org/impnotes/pcre.html.
- 新しい関数 RAWSOCK:IF-NAME-INDEX, RAWSOCK:IFADDRS が追加されました。 http://clisp.cons.org/impnotes/rawsock.html.
CLISP の新機能 (2.39)
- SAVEINITMEM 関数は :SCRIPT 引数を受けとれるようになりました.これは, 第一引数をスクリプト名として受けとる機能を無効にできます.また,:DOCUMENTATION 引数は新しい -help-image コマンドライン引数で表示するメッセージを指定できます. 詳細は http://clisp.cons.org/impnotes/image.html や http://clisp.cons.org/impnotes/clisp.html#opt-help-image を参照してください.
- FFI:UINT64 や FFI:SINT64 は C の long long 型と互換性を持つようになりました.
- スタックオーバーフロー検知・回復が UNIX 上でうまく動作するようになり ました.このために libsigsegv ライブラリが必要が MS-Windows を含む全 てのプラットフォームで必要になります.CLISP は無限再帰に落ちいった場 合に終了すべきでもクラッシュすべきでもありません.もし,お使いのディ ストリビューションで libsigsegv 無しでビルドされていたら,それは機能 不足としてメンテナーに報告してください.libsigsegv 2.4 が必要なことに 注意してください.libsigsegv 2.3 にはバグがあります!
- ジェネリック関数にデフォルトのメソッドコンビネーションが指定できるよ うになりました.DEFGENERIC フォームに :METHOD-COMBINATION が明示され なかった場合に,ジェネリック関数クラスの initarg 指定子 :METHOD-COMBINATION キーワードで指定されたものが適用されます.
- Readline 補完が UTF-8 のような非 1:1 端末エンコーディングでも動作するようになりました.
- WITH-KEYBOARD は SLIME が TERMINAL-IO 場合でも UNIX tty 上で動作するようになりました.
- Win32 の I/O 操作がより高速になりました.
- POSIX::FFS, POSIX::PATHCONF 関数が追加されました.
-
基盤:
- トップレベルの configure は新しいオプション –with-gmalloc を受け付けるようになりました. これは libc が提供する malloc のかわりに GNU malloc の実装を使用します.これは古い HP-UX や 最近の OpenBSD で必要になるかもしれません.詳しい情報は unix/PLATFORMS ファイルを参照してください.
- CFLAGS 環境変数の値が利用されるようになりました.
-
バグ修正:
- SOCKET:SOCKET-SERVER :INTERFACE はドキュメント通りの動作をするようになりました.
- EXT:READ-BYTE-NO-HANG や SOCKET:SOCKET-STATUS はバッファリングされたソケットで使われるようになりました.
- DESTRUCTURING-BIND (a . b) が巡回を含むリストやドットペアも許すようになりました.
- ADJUST-ARRAY を長さゼロの文字列に適用できるようになりました.
- TIME はヒープサイズが 4GB を超えた場合でも正しい結果を報告するようになりました.
- RAWSOCK 関数は :START/:END 引数と正しく取り扱えるようになりました.
- BDB:DBC-GET は :READ-COMMITTED や :READ-UNCOMMITTED を受けつけるようになりました.
- POSIX:GROUP-INFO や POSIX:USER-INFO はエラーを正しく扱えるようになりました.
-
移植性の向上:
- DragonFly BSD がサポートされるようになりました.
Win32 上での I/O の高速化
このバージョンから win32aux.d の DoInterruptible が `改良`_ されました. 今迄割り込み可能な I/O 毎に CreateThread でスレッドを生成するという聞く からに遅いコードから,イベントを使うコード(CreateEvent を試してだめだっ たら CreateThread へ…となりました)になりました.ちなみに作者の Bruno 氏も Windows で動けばいいやと考えて Thread API の `勉強がてら適当に作った`_ と ML で認めています.パッチ作者の Arseny Slobodyuk に感謝!!
効果は I/O 回数に比例するので Bufferd I/O ではあまり影響がないようです が,非 Bufferd I/O (:bufferd を nil) だと大幅に性能が向上しているようです.
.. `改良`: http://clisp.cvs.sourceforge.net/clisp/clisp/src/win32aux.d?r1=1.48&r2=1.49 .. `勉強がてら適当に作った`: http://sourceforge.net/mailarchive/forum.php?threadid=10297501&forumid=6768
CLISP の新機能 (2.38 〜 2.41)
- 2.41 から libsvm モジュールが追加されました。(win32 ではそのままでは利用できませんが)
- 2.40 から OPTIMIZE SPACE の設定が弱ければコンパイル後もラムダリストが保持されるようになりました。 SLIME で引数名が正しく表示されます
- 2.38 から (saveinitmem "hello" :executable t) とすることで 実行形式を生成できるようになりました 。Windows なら .exe が出力されます
- 大文字、小文字を区別する modern モード
CLISP for Win32 日本語 (SLIME + 各種ライブラリ + LTK ごった煮版)
-
clisp-2.46-full.zip:
私の普段使い始める時の基本環境です.とりあえず LISP で遊びたい人向けに SLIME と LTK に加えて
各種ライブラリを追加しました.Tclkit を含んでいるので,これだけで簡単な GUI 作成まで可能です.
[最終更新 2006-12-14]
- LTK : シンプルな GUI ライブラリ (アーカイブ内に Tclkit を含んでいますので即利用可能です)
- SWANK : SLIME 用バックエンド
- ASDF : C でいう make のようなユーティリティ
- CL-FAD : ファイルとディレクトリの取り扱い
- CL-PPCRE : 正規表現 (ただし,REGEX ライブラリのほうが高速です)
- CL-WHO : HTML 生成用ライブラリ
- CL-YACC : LISP 用パーサージェネレータ
- CL-UNIFICATION : ユニィフィケーション用ライブラリ
- CL-UTILITIES : 便利な関数のつまったライブラリ
- LISA : エージェントシステム
- ITERATE : Lisp ライクな LOOP マクロ
-
CFFI : 外部関数呼び出しのための共通基盤
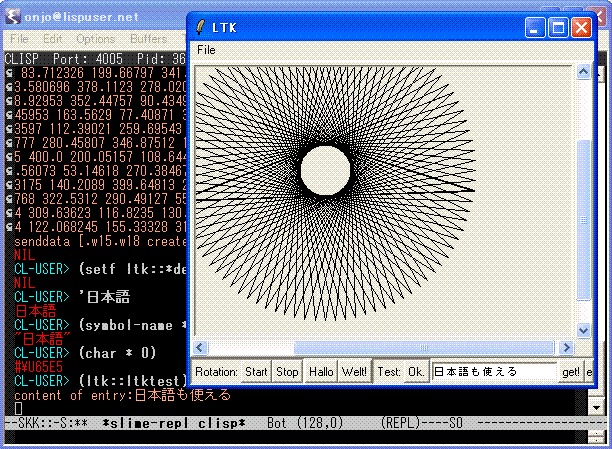
CLISP for Win32 日本語の使い方
コンソールから使うと制限が多いので,Emacs と SLIME を組み合わせて使います. Emacs は Takashi Hiromatsu さんの NTEmacs のバイナリ を使うと便利です.
clisp-2.46-full.zip を任意の場所に展開し,clisp-directory のパスを調 整して,御自分の .emacs の中に内容をすべてコピーしてください.
;;; -*- mode: emacs-lisp coding: shift_jis -*- ;;; ;;; CLISP & SLIME package ;;; ;;; 1. clisp-directory をインストールパスに合わせて設定する ;;; 2. M-x clisp-start ;;; 3. M-x slime-connect ;;; ;;; Tips: HyperSpec をダウンロードしてパスを設定しておくと便利です ;;; (setq clisp-directory "/home/onjo/lisp/clisp-2.46-full") ;;; ここを書き換えてください!! (setq slime-directory (concat clisp-directory "/slime")) (pushnew slime-directory load-path) ;; 以下省略
そして,M-x eval-buffer で評価するか,emacs を再起動するかして .emacs の内容を有効にした後,
M-x clisp-start M-x slime-connect
の順でタイプすることで SLIME を使い始める事ができます.Emacs と組み合わ せればフルセットの Lisp 開発環境です!! Happy Hacking!!
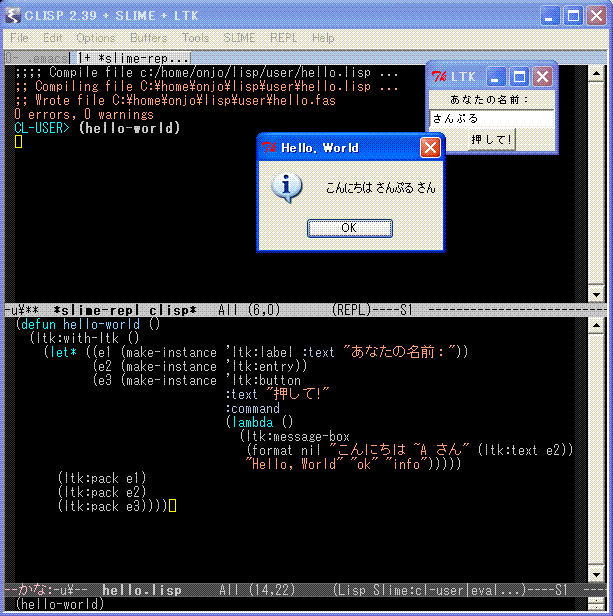
まだ何のサンプルもありませんが,使用例やサンプルについては今後,徐々に 増していけたら良いなーと思ってます.
さらに Common Lisp Hyper Spec ( 最新版 ) を ~/doc/HyperSpec に置いておくと `C-c H` で Common Lisp の関数/変数のドキュメントが参照できます.
CLISP for Win32 の制限
-
DOS 窓から起動した場合,日本語の入力が行えない (SLIME 経由で使う場合には問題ありません)
- DOS 窓から使う機会がないので追っていません.libreadline か libncurses あたりが日本語非対応なのかな?
-
SHIFT-JIS エンコーディングでニバイト目に '\' を含む文字(#\表 など)が,パスに含まれているとエラーになります.
pathnames.c の中でそのようなケースが考慮されていないためのようです.どうしたもんですかねぇ…….
- Perl : 日本語を含むパスの取り扱いに制限があります.
- Python : 内部 Unicode のため,問題ない(らしい?).
CLISP 用コアファイルのビルドスクリプト
#!/home/onjo/local/bin/clisp -K full -Emisc 1:1
(write-line ";;; Loading Libraries ...")
(eval-when (:load :execute)
(setf (getenv "LANG") "C")
;;(compile-file "~/lisp/site/asdf/asdf")
;;(load "~/lisp/site/asdf/asdf")
(compile-file "~/lisp/build/sbcl/contrib/asdf/asdf")
(load "~/lisp/build/sbcl/contrib/asdf/asdf"))
(pushnew
(merge-pathnames "lisp/asd/" (user-homedir-pathname))
asdf::*central-registry*)
(asdf:oos 'asdf:load-op :cl-fad)
(asdf:oos 'asdf:load-op :cl-interpol)
(asdf:oos 'asdf:load-op :cl-ppcre)
(asdf:oos 'asdf:load-op :cl-who)
(asdf:oos 'asdf:load-op :html-template)
#-clisp (asdf:oos 'asdf:load-op :hunchentoot)
(asdf:oos 'asdf:load-op :drakma)
(asdf:oos 'asdf:load-op :unification)
(asdf:oos 'asdf:load-op :cl-dot)
#-sbcl (asdf:oos 'asdf:load-op :md5)
(asdf:oos 'asdf:load-op :xmls)
(asdf:oos 'asdf:load-op :s-xml)
#+sbcl (asdf:oos 'asdf:load-op :s-xml-rpc)
(asdf:oos 'asdf:load-op :cffi)
(asdf:oos 'asdf:load-op :cffi-uffi-compat)
(asdf:oos 'asdf:load-op :cl-gd)
(asdf:oos 'asdf:load-op :yacc)
(asdf:oos 'asdf:load-op :kmrcl)
(asdf:oos 'asdf:load-op :cl-plus)
(asdf:oos 'asdf:load-op :cl-utilities)
(asdf:oos 'asdf:load-op :parenscript)
(asdf:oos 'asdf:load-op :cl-json)
(asdf:oos 'asdf:load-op :alexandria)
(asdf:oos 'asdf:load-op :arnesi)
#-clisp
(asdf:oos 'asdf:load-op :fiveam)
(asdf:oos 'asdf:load-op :cells)
(asdf:oos 'asdf:load-op :skippy)
(asdf:oos 'asdf:load-op :screamer)
(asdf:oos 'asdf:load-op :iterate)
(asdf:oos 'asdf:load-op :log4cl)
(asdf:oos 'asdf:load-op :series)
(asdf:oos 'asdf:load-op :ironclad)
(asdf:oos 'asdf:load-op :swank)
#-clisp
(asdf:oos 'asdf:load-op :pg)
;(asdf:oos 'asdf:load-op :clsql)
;(asdf:oos 'asdf:load-op :clsql-uffi)
;(clsql-sys::push-library-path #p"/usr/lib/")
;(asdf:oos 'asdf:load-op :clsql-sqlite3)
;(cffi:load-foreign-library "libsqlite3.so")
;(setf cffi:*foreign-library-directories* '(#P"/home/onjo/lisp/lib/base/clsql-3.8.1/uffi/"))
;(cffi:load-foreign-library "clsql_uffi.so")
;;(asdf:oos 'asdf:load-op :uffi)
(asdf:oos 'asdf:load-op :curl)
(asdf:oos 'asdf:load-op :puri)
(asdf:oos 'asdf:load-op :acl-compat)
(asdf:oos 'asdf:load-op :htmlgen)
#-clisp
(asdf:oos 'asdf:load-op :aserve)
#-clisp
(asdf:oos 'asdf:load-op :webactions)
#+sbcl
(asdf:oos 'asdf:load-op :hunchentoot)
(asdf:oos 'asdf:load-op :lw-compat)
(asdf:oos 'asdf:load-op :closer-mop)
(asdf:oos 'asdf:load-op :contextl)
(asdf:oos 'asdf:load-op :cldoc)
(asdf:oos 'asdf:load-op :html-encode)
;; (asdf:oos 'asdf:load-op :colorize)
(asdf:oos 'asdf:load-op :runes)
(asdf:oos 'asdf:load-op :cxml)
;; #+clisp (asdf:oos 'asdf:load-op :clisp-sqlite)
(asdf:oos 'asdf:load-op :rt)
#-clisp
;(asdf:oos 'asdf:load-op :bordeaux-threads)
#-clisp
;(asdf:oos 'asdf:load-op :timer)
#-clisp
;(asdf:oos 'asdf:load-op :cl-muproc)
(asdf:oos 'asdf:load-op :pygen)
(asdf:oos 'asdf:load-op :packer)
(asdf:oos 'asdf:load-op :trivial-sockets)
(asdf:oos 'asdf:load-op :trivial-gray-streams)
(asdf:oos 'asdf:load-op :flexi-streams)
(asdf:oos 'asdf:load-op :iso8601-date)
(asdf:oos 'asdf:load-op :local-time)
(asdf:oos 'asdf:load-op :cl-store)
(asdf:oos 'asdf:load-op :cl-prevalence)
;; (load (merge-pathnames "lisp/unstable/lisa/install.lisp" (user-homedir-pathname)))
(asdf:oos 'asdf:load-op :moptilities)
(asdf:oos 'asdf:load-op :asdf-system-connections)
(asdf:oos 'asdf:load-op :cl-containers)
(asdf:oos 'asdf:load-op :metatilities-base)
(asdf:oos 'asdf:load-op :metatilities)
(asdf:oos 'asdf:load-op :metabang-dynamic-classes)
(asdf:oos 'asdf:load-op :metabang-bind)
(asdf:oos 'asdf:load-op :defsystem-compatibility)
(asdf:oos 'asdf:load-op :cl-mathstats)
#-clisp
(asdf:oos 'asdf:load-op :cl-variates)
(asdf:oos 'asdf:load-op :cl-markdown)
;(without-package-lock (clos)
; (load "~/lisp/lib/common/lisa/install.lisp"))
;(without-package-lock (clos)
; (load "~/lisp/lib/common/lisa/install-clisp.lisp"))
(asdf:oos 'asdf:load-op :lisa)
(load (merge-pathnames "lisp/lib/common/XML/Load-XMLisp.lisp" (user-homedir-pathname)))
(in-package :cl-user)
;;; clocc
(load "/home/onjo/lisp/lib/common/clocc/clocc")
(compile-file (translate-logical-pathname "clocc:src;defsystem;defsystem"))
(load (translate-logical-pathname "clocc:src;defsystem;defsystem"))
;; * compile some systems
(dolist (l '("clocc:src;port;" "clocc:src;cllib;" "clocc:src;ext;queues;"
"clocc:src;port;configuration;" "clocc:src;port;environment;"
"clocc:src;ext;union-find;" "clocc:src;tools;metering;"
#+nil"clocc:src;f2cl;" #+nil"clocc:src;f2cl;packages;"))
(mk:add-registry-location (translate-logical-pathname l)))
(mk:oos "port" :compile)
;;(mk:oos "cllib" :compile)
;;(mk:oos "metering" :compile)
(mk:oos "port" :load)
;;(mk:oos "cllib" :load)
#+clisp
(gc)
#+sbcl
(gc :full t)
(load "../lib/unstable/maxima/src/maxima.system")
(mk:compile-system :maxima)
(mk:load-system :maxima)
(write-line ";;; Dump image ...")
#+clisp
(loop repeat 100 do (gc))
(saveinitmem "lispinit" :init-function #'(lambda ()
(cffi:load-foreign-library "libcurl.so")
(cffi:load-foreign-library "/home/onjo/lisp/lib/unstable/cl-curl/clcurl.so")))
(when (probe-file "clisp.mem")
(delete-file "clisp.mem"))
(rename-file "lispinit.mem" "clisp.mem")
(write-line ";;; Setup ShellScript ...")
(with-open-file (s "~/bin/clisp" :direction :output :if-exists :supersede)
(write-line "#!/bin/sh" s)
;(format s "~A -modern -K full -M ~A $@"
(format s "~A -K full -M ~A $@"
(namestring #p"~/local/bin/clisp")
(namestring #p"~/lisp/build/clisp.mem")))
CLISP 拡張モジュール HOWTO
ちょっと長いので CLISP拡張モジュールHOWTO へ分離しました。
リンク集
- Common Lisp Application Builder - 簡単アプリケーション配布のためのプロジェクト (プロジェクトページ)
CLISP IMPNOTES 翻訳
30.5 エンコーディング
30.5.1. 導入 (Introduction)
エンコーディング (encoding) はストリーム (STREAM) を経由した入出力の間 の文字列 (CHARACTERs) とバイト列の対応関係です.
EXT:ENCODING は次ような要素から構成されるオブジェクトです.
文字セット (character set)
これは表現可能な文字と,I/O チャネルを通して渡される文字 (CHARACTER) の集合です.これに従って文字はバイト列に変換されます. つまり,文字列と (VECTOR (UNSIGNED-BYTE 8)) の対応や,文字ストリー ムとバイトストリームとの対応における「文字と (UNSIGNED-BYTE 8) の対 応」の集合です.このコンテキストでは,例えば CHARSET:UTF-8 と CHARSET:UCS-4 は同じ文字集合を表現していますが,異なるエンコーディ ングであるという事になります.
行終端モード (line terminator mode)
これは,改行文字の表現方法を規定します.
EXT:ENCODING は型でもあります.それは,文字集合内で符号化可能な文字の集 合を表現します.このコンテキストでは,文字列からバイト列への変換方法は 無視されます.また,行終端モードも同様に無視されます.TYPEP や SUBTYPEP はエンコーディング型にたいして使用可能です
(SUBTYPEP CHARSET:UTF-8 CHARSET:UTF-16) ? T ; ? T (SUBTYPEP CHARSET:UTF-16 CHARSET:UTF-8) ? T ; ? T (SUBTYPEP CHARSET:ASCII CHARSET:ISO-8859-1) ? T ; ? T (SUBTYPEP CHARSET:ISO-8859-1 CHARSET:ASCII) ? NIL ; ? T
30.5.2. 文字セット (Character Sets)
プラットフォーム依存
CLISP をコンパイル時の UNICODE フラグなしでコンパイルすると,一つの文字 セット(プラットフォームネイティブの 8bit 文字セット)のみが使える状態 になります.CLHS の 13 章,文字列の章を参照してください [CHLS-13].
プラットフォーム依存
コンパイル時に UNICODE フラグありでコンパイルした場合のみ,以下の文字セッ トがサポートされます.CHARSET パッケージの定数シンボルに対応した値とし て見えます.
CHARSET パッケージ内のシンボル
- UCS-2 = UNICODE-16 = UNICODE-16-BIG-ENDIAN は UNICODE 文字集合 の 16-bit 基本多言語プレーンです.すべての文字は二バイトで表現 されます.
- UNICODE-16-LITTLE-ENDIAN
- UCS-4 = UNICODE-32 = UNICODE-32-BIG-ENDIAN は 21-bit UNICODE 文 字集合です.全ての文字は 4 バイトで表現されます.このエンコーディ ングは CLISP の内部で使用されています.
- UNICODE-32-LITTLE-ENDIAN
- UTF-8 は 21-bit UNICODE 文字集合です.すべての文字は 1 バイト 〜 4 バイトで表現されます.ASCII 文字は ASCII エンコーディング と同一の一バイトで表現されます.ほんとんどの Latin/Greek/Cyrillic/Hebrew 文字は 1 文字あたり 2 バイトで表現 されます.その他の殆どの文字は 1 文字あたり 3 バイトで表現され ます.まれに, 1 文字あたり 4 バイトを必要とする文字があります. したがって,一般的に全ての UNICODE エンコーディングのなかでもっ とも空間効率のよい Unicode です.
- UTF-16 は 21-bit UNICODE 文字集合です.16bit 基本多言語プレーン の全ての文字は 2 バイトで表現され,残りの文字は一文字あたり 4 バイトで表現されます.この文字集合はGNU libc もしくは GNU libiconv が利用可能なプラットフォームでのみ使用できます.
- UTF-7 は 21-bit UNICODE 文字集合です.これはステートフルな 7-bit エンコーディングです.すべての ASCII 文字が自身を表すわけ ではありません.この文字集合はGNU libc もしくは GNU libiconv が 利用可能なプラットフォームでのみ使用できます.
- JAVA は 21-bit UNICODE 文字集合です.ASCII 文字はそれ自身を表し, 1 文字は 1 バイトです.基本他言語プレーンの ASCII 以外の全ての 文字は\unnnn (nnnn は 16 進数) で表現され,1 文字を表すのに 6 バイト必要です.残りの文字は \uxxxx\uyyyy で表現され,1 文字あ たり 12 バイトです.このヘンコーディングは ASCII のみ対応のツー ルやエディタを使ってファイルを編集するには非常に適していますが, UNICODE 文字すべてを含むテキストの信頼性のある表現は不可能です. このエンコーディングでは \u (バックスラッシュにつづけて,小文字 の u) を含まないテキストに関してのみ,信頼できる表現が可能です.
- ASCII は広く使われている US 向けの 7-bit 文字集合です (ASCII - American Standard Code for Information Interchange)
-
ISO-8859-1 は ASCII 文字集合を Afrikaans, Albanian, Basque,
Breton, Catalan, Cornish, Danish, Dutch, English, F?roese,
Finnish, French, Frisian, Galician, German, Greenlandic,
Icelandic, Irish, Italian, Latin, Luxemburgish, Norwegian,
Portuguese, R?to-Romanic, Scottish, Spanish, Swedish などの各国
の言語用に拡張したものです.
このエンコーディングは非常に良い性質を持っています.
::
(LOOP :for i :from 0 :to CHAR-CODE-LIMIT :for c = (CODE-CHAR i) :always (OR (NOT (TYPEP c CHARSET:ISO-8859-1)) (EQUALP (EXT:CONVERT-STRING-TO-BYTES (STRING c) CHARSET:ISO-8859-1) (VECTOR i)))) ? T
例えば,CLISP の CODE-CHAR/CHAR-CODE はそれぞれの領域で互換性が あります.
- ISO-8859-2 は ASCII 文字集合を Croatian, Czech, German, Hungarian, Polish, Slovak, Slovenian, Sorbian などの言語向けに するための拡張です.
- ISO-8859-3 は ASCII 文字集合を Esperanto や Maltese などの言語 向けにするための拡張です.
- ISO-8859-4 は ASCII 文字集合を Estonian, Latvian, Lithuanian, Sami (Lappish) などの言語向けに拡張したものです.
- ISO-8859-5 は ASCII 文字集合を Bulgarian, Byelorussian, Macedonian, Russian, Serbian, Ukrainian などの言語向けにするた めの拡張です.
- ISO-8859-6 は Arabic 言語向けです.
- ISO-8859-7 は Greek 言語向けの ASCII 文字集合の拡張です.
- ISO-8859-8 は Hebrew 言語(punctuation なし)向けの ASCII 文字集合の拡張です.
- ISO-8859-9 は Turkish 言語向けの ASCII 文字集合の拡張です.
- ISO-8859-10 は Estonian, Icelandic, Inuit (Greenlandic), Latvian, Lithuanian, Sami (Lappish) 言語向けの ASCII 文字集合の 拡張です.
- ISO-8859-13 は Estonian, Latvian, Lithuanian, Polish, Sami (Lappish) 言語向けの ASCII 文字集合の拡張です.
- ISO-8859-14 は Irish G?lic, Manx G?lic, Scottish G?lic, Welsh 言語 向けの ASCII 文字集合の拡張です.
- ISO-8859-15 は ISO-8859-1 の French, Finnish, Euro サポートを加 えた ASCII 文字集合の拡張です.
- ISO-8859-16 は Rumanian 言語向けの ASCII 文字集合の拡張です.
- KOI8-R は Russian 言語 (特にインターネットでポピュラーです) 向 けの ASCII 文字集合の拡張です.
- KOI8-U は Ukrainian 言語(特にインターネットでポピュラーです) 向けの ASCII 文字集合の拡張です.
- KOI8-RU は Russian 言語向けの ASCII 文字集合の拡張です.この文 字集合は GNU libiconv が利用可能なプラットフォームでのみサポー トされます.
- JISX0201 は日本語の文字集合です.
- MAC-ARABIC は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-CENTRAL-EUROPE は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-CROATIAN は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-CYRILLIC は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-DINGBAT はプラットフォーム固有の文字集合です.
- MAC-GREEK はプラットフォーム固有の文字集合です.
- MAC-HEBREW はプラットフォーム固有の文字集合です.
- MAC-ICELAND はプラットフォーム固有の文字集合です.
- MAC-ROMAN = MACINTOSH はプラットフォーム固有の文字集合です.
- MAC-ROMANIA は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-SYMBOL は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-THAI は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-TURKISH は ASCII 文字集合のプラットフォーム固有拡張です.
- MAC-UKRAINE は ASCII 文字集合のプラットフォーム固有拡張です.
- CP437 は DOS 時代からの古株で,ASCII 文字集合のプラットフォーム 固有拡張です.
- CP437-IBM は CP437 の IBM による変種です.
- CP737 は DOS 時代からの古株で,Greek 言語に対応した ASCII 文字 集合のプラットフォーム固有拡張です.
- CP775 は DOS 時代からの古株で,Baltic 言語に対応した ASCII 文字 集合のプラットフォーム固有拡張です.
- CP850 は DOS 時代からの古株で,ASCII 文字集合のプラットフォーム 固有拡張です.
- CP852 は DOS 時代からの古株で,ASCII 文字集合のプラットフォーム 固有拡張です.
- CP852-IBM は CP852 の IBM による変種です.
- CP855 は DOS 時代からの古株で,Russian 言語に対応した ASCII 文字集合のプラットフォーム固有拡張です.
- CP857 は DOS 時代からの古株で,Turkish 言語に対応した ASCII 文 字集合のプラットフォーム固有拡張です.
- CP860 は DOS 時代からの古株で,Turkish 言語に対応した ASCII 文 字集合のプラットフォーム固有拡張です.
- CP860-IBM は CP860 の IBM による変種です.
- CP861 は DOS 時代からの古株で,Icelandic 言語に対応した ASCII 文字集合のプラットフォーム固有拡張です.
- CP861-IBM は CP861 の IBM による変種です.
- CP862 は DOS 時代からの古株で,Hebrew 言語に対応した ASCII 文字 集合のプラットフォーム固有拡張です.
- CP862-IBM は CP862 の IBM による変種です.
- CP863 は DOS 時代からの古株で,文字集合のプラットフォーム固有拡 張です.
- CP863-IBM は CP863 の IBM による変種です.
- CP864 は DOS 時代からの古株で,Arabic 言語向けのものです.
- CP864-IBM は CP864 の IBM による変種です.
- CP865 は DOS 時代からの古株で,いくつかの Nordic 言語に対応した 文字集合のプラットフォーム固有拡張です.
- CP865-IBM は CP865 の IBM による拡張です.
- CP866 は DOS 時代からの古株で,Russian 言語に対応した文字集合の プラットフォーム固有拡張です.
- CP869 は DOS 時代からの古株で,Greek 言語に対応した文字集合の プラットフォーム固有拡張です.
- CP869-IBM は CP869 の IBM による変種です.
- CP874 は DOS 時代からの古株で,Thai 言語に対応した文字集合の プラットフォーム固有拡張です.
- CP874-IBM は CP874 の IBM による変種です.
- WINDOWS-1250 ? CP1250 はプラットフォーム固有な ASCII 文字集合の 拡張です.ISO-8859-2 との酷い非互換があります.
- WINDOWS-1251 ? CP1251 は Russian 言語向けのプラットフォーム固有 な ASCII 文字集合の拡張です.ISO-8859-5 との酷い非互換があります.
- WINDOWS-1252 ? CP1252 はプラットフォーム固有な ISO-8859-1 の拡 張です.
- WINDOWS-1253 ? CP1253 は Greek 言語向けのプラットフォーム固有な ASCII 文字集合の拡 張です. ISO-8859-7 との非互換があります.
- WINDOWS-1254 ? CP1254 はプラットフォーム固有な ISO-8859-9 文字集合の拡 張です.
- WINDOWS-1255 ? CP1255 は Hebrew 言語向けのプラットフォーム固有 な ASCII 文字集合の拡張です.ISO-8859-8 との非互換があります. この文字集合は GNU libc もしくは GNU libiconv が利用可能な プラットフォームでのみ利用できます.
- WINDOWS-1256 ? CP1256 は Arabic 言語向けのプラットフォーム固有 な ASCII 文字集合の拡張です.
- WINDOWS-1257 ? CP1257 は Aプラットフォーム固有な ASCII 文字集合 の拡張です.
- WINDOWS-1258 ? CP1258 は Vietnamese 言語向けのプラットフォーム 固有な ASCII 文字集合の拡張です.この文字集合は GNU libc もしく は GNU libiconv が利用可能なプラットフォームでのみ利用できます.
- HP-ROMAN8 は ASCII 文字集合のプラットフォーム固有拡張です.
- NEXTSTEP は ASCII 文字集合のプラットフォーム固有拡張です.
- EUC-JP は日本語向けのマルチバイト文字集合です.この文字集合は, GNU libc もしくは GNU libiconv が利用可能なプラットフォームでの み使用できます.
- SHIFT-JIS は日本語向けのマルチバイト文字集合です.この文字集合は, GNU libc もしくは GNU libiconv が利用可能なプラットフォームでの み使用できます.
- CP932 は SHIFT-JIS の Microsoft による変種です.この文字集合は, GNU libc もしくは GNU libiconv が利用可能なプラットフォームでの み使用できます.
- ISO-2022-JP は日本語向けのステートフルな 7bit マルチバイト文字 集合です.この文字集合は GNU libc もしくは GNU libiconv が利用 可能なプラットフォームでのみ使用できます.
- ISO-2022-JP-2 は日本語向けのステートフルな 7bit マルチバイト文字 集合です.この文字集合は GNU libc もしくは GNU libiconv が利用 可能なプラットフォームでのみ使用できます.
- ISO-2022-JP-1 は日本語向けのステートフルな 7bit マルチバイト文字 集合です.この文字集合は GNU libc もしくは GNU libiconv が利用 可能なプラットフォームでのみ使用できます.
- EUC-CN は中国語(簡体字)向けのマルチバイト文字集合です.この文 字集合は GNU libc もしくは GNU libiconv が利用可能なプラット フォームでのみ使用できます.
- HZ は中国語(簡体字)向けのステートフルな 7bit マルチバイト文字 集合です.この文字集合は GNU libiconv が利用可能なプラットフォー ムでのみ使用できます.
- GBK は中国語向けのマルチバイト文字集合です.この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォームでのみ使 用できます.
- CP936 は GBK の Microsoft による変種です.この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォームでのみ使 用できます.
- GB18030 は中国語向けのマルチバイト文字集合です.この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォームでのみ使 用できます.
- EUC-TW は中国語(繁体字)向けのマルチバイト文字集合です.この文 字集合は GNU libc もしくは GNU libiconv が利用可能なプラット フォームでのみ使用できます.
- BIG5 は中国語(繁体字)向けのマルチバイト文字集合です.この文字 集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォー ムでのみ使用できます.
- CP950 は BIG5 の Microsoft による変種です.この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォームでのみ使 用できます.
- BIG5-HKSCS は中国語(繁体字)向けのマルチバイト文字集合です.この文字 集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォー ムでのみ使用できます.
- ISO-2022-CN は中国語向けのステートフルな 7bit マルチバイト文字 集合です.この文字集合は GNU libc もしくは GNU libiconv が利用 可能なプラットフォームでのみ使用できます.
- ISO-2022-CN-EXT は中国語向けのステートフルな 7bit マルチバイト文字 集合です.この文字集合は GNU libc もしくは GNU libiconv が利用 可能なプラットフォームでのみ使用できます.
- EUC-KR は韓国語向けのマルチバイト文字集合です.この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォームでの み使用できます.
- CP949 は EUC-KR の Microsoft による変種です.この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォームでの み使用できます.
- ISO-2022-KR は韓国語のためのステートフルな 7bit マルチバイト文 字集合です.この文字集合は GNU libc もしくは GNU libiconv が利 用可能なプラットフォームでのみ使用できます.
- JOHAB はほんとど DOS 上でのみ使われる韓国語向けのマルチバイト文 字集合です.この文字集合は GNU libc もしくは GNU libiconv が利 用可能なプラットフォームでのみ使用できます.
- ARMSCII-8 はアメリカ向けの ASCII 文字集合の拡張です.この文字 集合は GNU libc もしくは GNU libiconv が利用可能なプラットフォー ムでのみ使用できます.
- GEORGIAN-ACADEMY は Georgian 向けの ASCII 文字集合の拡張です. この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラッ トフォームでのみ使用できます.
- GEORGIAN-PS は Georgian 向けの ASCII 文字集合の拡張です. この文字集合は GNU libc もしくは GNU libiconv が利用可能なプラッ トフォームでのみ使用できます.
- TIS-620 は Thai 向けの ASCII 文字集合の拡張です.この文字集合 は GNU libc もしくは GNU libiconv が利用可能なプラットフォーム でのみ使用できます.
- MULELAO-1 は Laotian 向けの ASCII 文字集合の拡張です.この文字集合 は GNU libc もしくは GNU libiconv が利用可能なプラットフォーム でのみ使用できます.
- CP1133 は Laotian 向けの ASCII 文字集合の拡張です.この文字集合 は GNU libc もしくは GNU libiconv が利用可能なプラットフォーム でのみ使用できます.
- VISCII は Vietnamese 向けの ASCII 文字集合の拡張です.この文字集合 は GNU libc もしくは GNU libiconv が利用可能なプラットフォーム でのみ使用できます.
- TCVN VISCII は Vietnamese 向けの ASCII 文字集合の拡張です.こ の文字集合は GNU libc もしくは GNU libiconv が利用可能なプラッ トフォームでのみ使用できます.
-
BASE64 は任意サイズのバイト列を 64 種類の ASCII 文字でエンコードします.
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
MIME で規定されているように,3byte を 4 文字で表現し,76 文字毎に 改行されます.
これは,伝統的な文字集合ではありませんが(自然言語中の文字をバ イトにマップしません),バイト列と文字列との関係を定義している ため,EXT:ENCODING クラスの中で規定されます.
プラットフォーム依存:
GNU libc 2.2 もしくはそれ以上を備えている GNU システムか,GNU libiconv ライブラリがインストールされている UNIX や Win32 環境での み利用可能です.
iconv ライブラリ関数によって提供させる文字集合がエンコーディン グとして使用可能です.エンコーディングは EXT:MAKE-ENCODING 関 数の :CHARSET 引数に文字集合名文字列を渡す事で作成できます.
EXT:ENCODING がビルトインのものと iconv ともに利用可能だった場 合にはビルトインのものが使われます.これは,より効率的で,かつ 全てのプラットフォームで後半に利用できるからです.
エンコーディングはグローバル変数には設定されていません.なぜな らば,iconv でサポートされている全ての文字集合のリストを得る方 法が無いからです.
標準的な UNIX システム(GNU/Linux や GNU/Hurd などの GNU シス テム)や GNU libiconv では `iconv -l` でこのリストを得る事がで きます.
我々が GNU libc 2.2 もしくは GNUl libiconv のみを使う理由は, 他の iconv 実装は多種多様に壊れているからです.我々は,それら のバグのによって CLISP がランダムにクラッシュする事までは面倒 をみたくありません.もし,あなたのお使いのシステムが GNU libiconv のテストスイートをパスする iconv の実装を提供している のなら,<clisp-list@lists.sourceforge.net> (http://lists.sourceforge.net/lists/listinfo/clisp-list) まで 報せてください.将来のバージョンの CLISP はその iconv を使うよ うになるでしょう.
30.5.3. 行終端 (Line Terminators) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
行終端モードは,以下の 3 つのキーワードのうちのいずれかです.
:UNIX
改行文字 #\Newline は ASCII の LF 文字 (U000A) で表現されます.
:MAC
改行文字 #\Newline は ASCII の CR 文字 (U000D) で表現されます.
:DOS
改行文字 #\Newline は ASCII の CR 文字 (U000D) と続く ASCII LF 文字 (U000A) で表現されます.
Windows プログラムはたいてい :DOS 行終端を使いますが,ときどき :UNIX 行 終端を受けつけたり :MAC 行終端を出力したりします.
HTTP プロトコルは :DOS 行終端を要求しています.
行終端モードはファイル/パイプ/ソケットなどへの出力に対してだけ意味があ ります.入力時には,3 種類全ての行終端が認識されます.CLHS の 13.8 節 `入出力における改行の扱い` [CHLS-13.1.8] を参照してください.
30.5.4. Function EXT:MAKE-ENCODING
関数 (EXT:MAKE-ENCODING &KEY :CHARSET :LINE-TERMINATOR :INPUT-ERROR-ACTION :OUTPUT-ERROR-ACTION) は EXT:ENCODING を返しま す.:CHARSET 引数はエンコーディング,文字列,もしくは :DEFAULT のいずれ かでなければなりません.:LINE-TERMINATOR 引数の値にはキーワード :UNIX, :MAC, :DOS のいずれかを指定してください.
:INPUT-ERROR-ACTION 引数は,バイト列を文字に変換している途中で,不正な バイト列が出現した時に何がおこるかを指定します.その値は :ERROR, :IGNORE, もしくは代りに使用される文字です.UNICODE 文字 #\uFFFD が入力 シーケンス中のエラーを表すのによく使用されます.
.. The :OUTPUT-ERROR-ACTION argument specifies what happens when an invalid character is encountered while converting characters to bytes. Its value can be :ERROR, :IGNORE, a byte to be used instead, or a character to be used instead. The UNICODE character #\uFFFD can be used here only if it is encodable in the character set.
:OUTPUT-ERROR-ACTION 引数は,文字をバイトに変換している途中で,不正な文 字が出現した場合に何がおこるかを指定します.その値は :ERROR, :IGNORE, もしくはかわりに使用される文字です.ユニコード文字 #\uFFFD は,それが文 字集合のなかでエンコード可能であった場合にのみ使用されます.
30.5.5. Function EXT:ENCODING-CHARSET
プラットフォーム依存:
CLISP が UNICODE コンパイル時フラグ付きでビルドされていた場合のみ使用可能です.
関数 (EXT:ENCODING-CHARSET encoding) は,エンコーディングの文字集合をシ ンボルもしくは文字列として返します.
Warning:
(STRING (EXT:ENCODING-CHARSET encoding)) は MIME 名として有効である必要はありません.
30.5.6. デフォルトエンコーディング (Default encodings)
ファイル/パイプ/ソケットなど全てのストリームはエンコーディングを含んで います.加えて下記の SYMBOL-MACRO はグローバルな EXT:ENCODING を含んで います.
SYMBOL-MACRO `CUSTOM:*DEFAULT-FILE-ENCODING*`. SYMBOL-MACRO `CUSTOM:*DEFAULT-FILE-ENCODING*` は新しく作成されるファイル/パイプ/ソケッ ト ストリームで :EXTERNAL-FORMAT 引数が指定されていない場合に使われるエ ンコーディングです.
プラットフォーム依存:
CLISP が UNICODE コンパイル時フラグ付きでビルドされていた場合のみ使用可能です.
下記の SYMBOL-MACRO が存在します.
`CUSTOM:*PATHNAME-ENCODING*`:
ファイルシステム中のパス名に使われるエンコーディングです.通常 1:1 エンコーディングを使用すべきです.行終端モードは無視されます.
`CUSTOM:*TERMINAL-ENCODING*`:
端末とのやりとり,特に `*TERMINAL-IO*` ストリームで使用されるエンコー ディングです.
`CUSTOM:*MISC-ENCODING*`:
環境変数やコマンドラインオプションなどにアクセスする際に使用される エンコーディングです.行終端モードは無視されます.
`CUSTOM:*FOREIGN-ENCODING*`:
?FFI? (使用できるプラットフォームは限定されています) を通じてやり とりする文字列で使用されます.もしすべての文字が 1 バイトに対応して いる 1:1 エンコーディングが設定されているならば,そのエンコーディン グが使用されます.
.. is the encoding for strings passed through the ?FFI? (some platforms only). If it is a 1:1 encoding, i.e. an encoding in which every character is represented by one byte, it is also used for passing characters through the ?FFI?.
デフォルトエンコーディングオブジェクトは `-Edomain enconding` 引数に従っ て初期化されます.
Reminder:
SYMBOL-MACRO に対しては EXT:LETF/EXT:LETF を使う必要があります.LET/LET* は正しく動作しません!
30.5.7. 文字列とバイト列間の変換 (Converting between strings and byte vectors)
エンコーディングは文字列と対応するエンコーディングに従ったバイトベクタ 表現との変換にも使用されます.
`(EXT:CONVERT-STRING-FROM-BYTES vector encoding &KEY :START :END)`
`(VECTOR (UNSIGNED-BYTE 8))` ベクタの :start から :end で指定された 部分シークエンスを与えられたエンコーディングに従って文字列に変換し, 変換した文字列を返します.
`(EXT:CONVERT-STRING-TO-BYTES string encoding &KEY :START :END)`
文字列の :start から :end で指定された部分文字列を,指定されたエン コーディングに従って `(VECTOR (UNSIGNED-BYTE 8))` のバイト列に変換 し,変換した結果のバイトベクタを返します.
$Last Update: 2007/09/09 21:18:48 $